
varint 编码简要介绍
引言
不论是网络传输,还是将数据写入到存储设备中,都需要将内存中的数据进行序列化,并且需要在使用时将其反序列化为原来的数据。因此,如何设计序列化方法让我们能够编码和解码数据就是我们要思考的问题。
如果数据涉及安全问题,我们可以使用各种加密算法对数据进行加密,但是如果数据没有加密的必要性,我们并不需要花费额外的开销在加密和解密上。
不管是什么类型的数据,读取的时候都是以字节流的形式读取的,所以我们并不能区分数据的界限。所以自定义编码格式是很有必要的。如果我们知道了数据的开头,该如何找到数据的结尾呢?最简单的方式是存储数据的长度,根据数据的长度,我们就可以找到数据的结尾。

这个想法很好,但是问题来了,我们怎么知道 length 需要花费多少字节存储呢?一个简单的想法是使用固定长度来存储,比如一个字节能够表示 255 字节的数据,对于比较小的数据来说已经足够了。但是如果有的数据非常大怎么办呢?使用 int 32 位来表示长度,这样我们就能存储 4G 的数据了。一般来说这是足够的,但是如果我们存储的数据可能更多地是小数据,这就会造成浪费。
那么有没有一种方法让我们既能够安全地存取数据,又能够节省空间呢?
Varint 编码
varint 编码不显示地存储数据地长度,而是换了一种方法。它在每个字节的 8 bit 中留出 1 位用来表示数据是否结束。如果该位为 1,表示数据还没有读取完,需要继续读取;如果为 0,表示这是数据的最后一个字节。比如数据 1234 的存储格式如下图所示(采用大端存储)
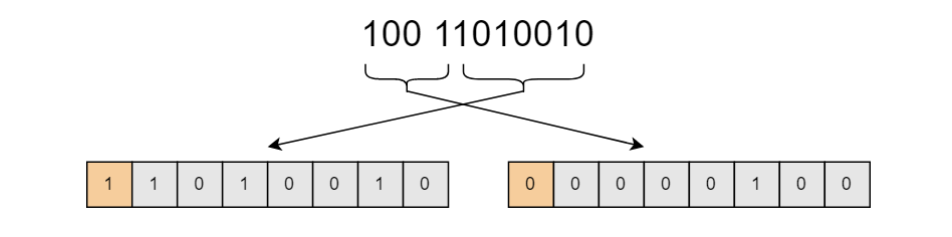
我们使用一个 byte 中的高 1 bit 表示数据是否结束,也就是说我们可以使用剩下的 7 bit 存储数据。数据利用率最好可以达到 ,最坏情况下也不会浪费超过 1 字节的空间,这个效果还不错。
实现
对于一个 uint64 类型的数据,我们可以使用位运算简单地实现
1 | char* EncodeVarint64(char* dst, uint64_t v) { |
解码也很简单
1 | char* GetVarint64Ptr(const char* p, uint64_t* value) { |

