概览
这一部分主要是实现 DB 的一些运算操作
根据已经提供的 Project 和 OrderBy,实现运算符 Filter 和 Join
实现 IntegerAggregator 和 StringAggregator。
实现聚合运算。聚合运算符的输出是每次调用 next() 时整个组的聚合值
在 BufferPool 中实现 tuple 的插入、删除、页牺牲等相关方法
实现插入和删除运算符
请注意,SimpleDB 不实现任何类型的一致性或完整性检查,因此可以将重复记录插入文件中,并且无法强制执行主键或外键约束。
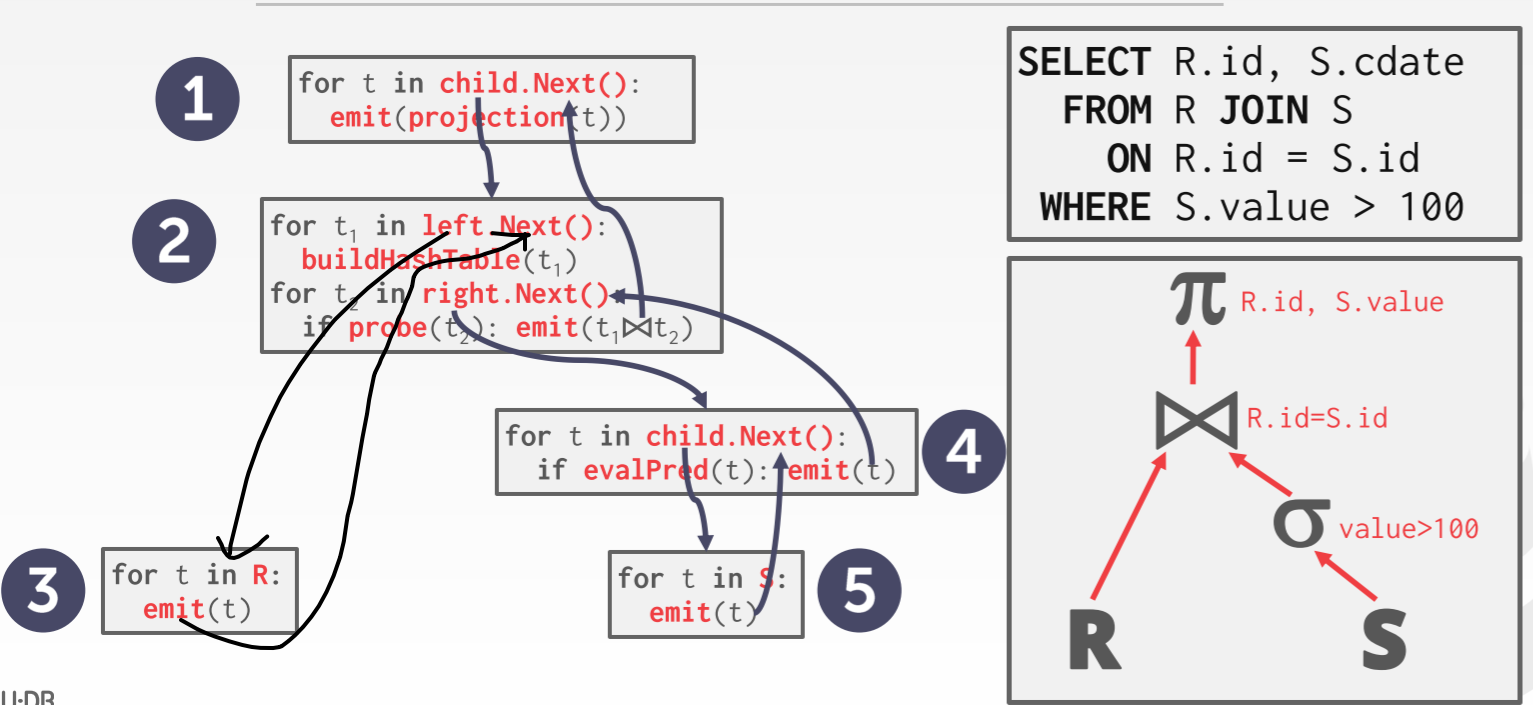
DB 使用迭代模型,以数据流的模型不断调用next方法获取数据流。
Predicate
Predicate 谓词,可以用来过滤。支持 =、>=、>、<=、<、<>、like 条件。
1 2 3 4 5 6 7 8 9 10 private Op op; private Field operand; private int field; public boolean filter (Tuple t) Field field = t.getField(this .field); if (field.compare(op, operand)) { return true ; } return false ; }
Filter
Filter 接受一个谓词和一个迭代器。下面语句中 id>=10 就是是谓词
1 select * from table where id >= 10 ;
1 2 3 4 5 public Filter (Predicate p, OpIterator child) this .predicate = p; this .child = child; this .tupleDesc = child.getTupleDesc(); }
Filter 继承自**Operator**,而 Operator 继承自 OpIterator。Operator 实现了hasNext() 和 next() 方法来获取下一条 Tuple,而观察其中发现都调用了 fetchNext() 该方法,而我们的 filter 就需要实现这个方法从而实现获取下一条符合条件的 tuple。
1 2 3 4 5 6 7 8 9 10 11 protected Tuple fetchNext () throws NoSuchElementException, TransactionAbortedException, DbException { if (!child.hasNext()) return null ; while (child.hasNext()) { Tuple t = child.next(); if (predicate.filter(t)) { return t; } } return null ; }
Project
Project 的作用接受输入,将指定属性作为输出。操作的具体过程是:接受需要投影的列的索引及其索引,构造出一个 TupleDesc,然后根据数据源,构建出新 Tuple
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public Project (List<Integer> fieldList, Type[] types, OpIterator child) this .child = child; outFieldIds = fieldList; String[] fieldAr = new String[fieldList.size()]; TupleDesc childtd = child.getTupleDesc(); for (int i = 0 ; i < fieldAr.length; i++) { fieldAr[i] = childtd.getFieldName(fieldList.get(i)); } td = new TupleDesc(types, fieldAr); } protected Tuple fetchNext () throws NoSuchElementException, TransactionAbortedException, DbException { if (!child.hasNext()) return null ; Tuple t = child.next(); Tuple newTuple = new Tuple(td); newTuple.setRecordId(t.getRecordId()); for (int i = 0 ; i < td.numFields(); i++) { newTuple.setField(i, t.getField(outFieldIds.get(i))); } return newTuple; }
OrderBy
OrderBy 可以保证输出已经是排好序的。它会从子操作中获取所有的数据,放入一个临时的 list 中,然后对 list 进行排序。当父操作需要数据时,将排好序的数据传送给父操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public OrderBy (int orderbyField, boolean asc, OpIterator child) this .child = child; td = child.getTupleDesc(); this .orderByField = orderbyField; this .orderByFieldName = td.getFieldName(orderbyField); this .asc = asc; childTups = new ArrayList<>(); } public void open () throws DbException, NoSuchElementException, TransactionAbortedException { child.open(); while (child.hasNext()) childTups.add(child.next()); childTups.sort(new TupleComparator(orderByField, asc)); it = childTups.iterator(); super .open(); }
Lab 中写了一个比较器,用来自定义比较规则。具体规则就是比较要排序的键,根据传入的 asc 决定是升序排序还是降序排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class TupleComparator implements Comparator <Tuple > final int field; final boolean asc; public TupleComparator (int field, boolean asc) this .field = field; this .asc = asc; } public int compare (Tuple o1, Tuple o2) Field t1 = (o1).getField(field); Field t2 = (o2).getField(field); if (t1.compare(Predicate.Op.EQUALS, t2)) return 0 ; if (t1.compare(Predicate.Op.GREATER_THAN, t2)) return asc ? 1 : -1 ; else return asc ? -1 : 1 ; } }
Join
DB 支持内连接。这里使用 Nested Loop Join,即从 a 取出一条,遍历 b,符合的就构造出新的 tuple然后加到结果集中。可以使用 Merge Sort 或 Hash Join 优化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 select a.* , b.* from a inner join b on a.id = b.id; protected Tuple fetchNext() throws TransactionAbortedException, DbException { while (t1 != null || child1.hasNext()) { if (t1 = = null ) t1 = child1.next(); while (child2.hasNext() ) { // 对于 inner 每一条 tuple,遍历 outer Tuple t2 = child2.next(); if (predicate.filter(t1, t2)) { Tuple tuple = new Tuple(tupleDesc); Iterator< Field> it1 = t1.fields(); Iterator< Field> it2 = t2.fields(); int i = 0 ; while (it1.hasNext()) { // 属性赋值 tuple.setField(i + + , it1.next()); } while (it2.hasNext()) { tuple.setField(i + + , it2.next()); } return tuple; } } child2.rewind(); t1 = null ; } return null ; }
Aggregate
1 select SUM (nums) from table group by id;
这里需要实现聚合运算,包括 int 类型的聚合(支持 SUM, MAX, MIN, COUNT, AVG)和 String 类型的聚合(只支持 COUNT)。除了聚合,我们还支持分组操作。groupByField 为 key,以聚合结果为 value。如果不需要分组,那么结果只有一组,只需要输出这一组就可以了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private class AggValue int count; int value; public AggValue (int value, int count) this .count = count; this .value = value; } public void increaseCount () count ++; } public int getCount () return count; } public int getValue () return value; } public void setValue (int value) this .value = value; } }
Insert
我们需要分别实现向 BufferPool,即 HeapPage 和 DBFile 即 HeapFile 中的 page 中插入 tuple。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public List<Page> insertTuple (TransactionId tid, Tuple t) throws DbException, IOException, TransactionAbortedException { int pgNum; for ( pgNum = 0 ; ; pgNum++) { HeapPageId pageId = new HeapPageId(getId(), pgNum); HeapPage page = (HeapPage) bufferPool.getPage(tid, pageId, Permissions.READ_WRITE); if (page.getNumEmptySlots() != 0 ) { page.insertTuple(t); if (pgNum >= numPages()) { writePage(page); } return Collections.singletonList(page); } else { bufferPool.unsafeReleasePage(tid, pageId); } } }
这里调用 HeapPage 的插入方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void insertTuple (Tuple t) throws DbException if (getNumEmptySlots() == 0 ) { throw new DbException("The page is full" ); } if (!td.equals(t.getTupleDesc())) { throw new DbException("Mismatch tuple." + t.toString()); } for (int i = 0 ; i < numSlots; i++) { if (!isSlotUsed(i)) { markSlotUsed(i, true ); t.setRecordId(new RecordId(pid, i)); tuples[i] = t; break ; } } }
Delete
对于 DBFile(这里暂时只考虑 HeapFile),我们需要根据 tuple 找到对应的 page,然后向 page 中插入 tuple。Tuple 中有一个 recordId 属性,其中存储了 pageId 和 tupleNumber。我们可以根据这个属性找到 tuple 在哪个 page,以及在 page 的哪个位置。具体实现和 Insert 差不多,甚至更简单,只需要将 HeapPage 的 slot 标记为未使用状态即可。
1 2 3 4 5 6 7 public List<Page> deleteTuple (TransactionId tid, Tuple t) throws DbException, TransactionAbortedException { RecordId recordId = t.getRecordId(); HeapPage page = (HeapPage) bufferPool.getPage(tid, recordId.getPageId(), Permissions.READ_WRITE); page.deleteTuple(t); return Collections.singletonList(page); }
注意 Insert 和 Delete 操作同其他操作一样,都是使用的迭代模型,都需要实现 next 方法(Lab 中会调用 fetchNext()),所以我们同样需要获取子操作传递的数据源,然后进行插入或删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private TransactionId tid;private OpIterator child; private int tableId; private TupleDesc td;private volatile boolean executed = false ; protected Tuple fetchNext () throws TransactionAbortedException, DbException if (executed) return null ; int count = 0 ; while (child.hasNext()) { Tuple t = child.next(); count ++; } Tuple t = new Tuple(new TupleDesc(new Type[]{Type.INT_TYPE})); t.setField(0 , new IntField(count)); executed = true ; return t; }
这里有一个问题:如何根据谓词条件删除?查看测试代码,可以发现有如下的代码:
1 2 Filter filter = new Filter(predicate, ss); Delete deleteOperator = new Delete(tid, filter);
我们之前说过,Filter 继承自**Operator**,而 Operator 继承自 OpIterator。在 Delete 的构造方法中接受的是 OpIterator,所以我们只需要将谓词传入 Delete 中即可。在调用数据源的 next 的方法时数据已经是过滤后的 tuple 了。