
15-445 Storage
DBMS 的一个设计目标是支持管理超过内存量的数据库。由于相较于读写内存,读写磁盘的开销比较大,因此必须小心地设计,让读写数据库地性能最大化。
文件布局
DMBS 将数据库以特定格式存储在磁盘上的一个或多个文件中,并使用存储管理器(storage manager)进行管理。存储管理器将文件抽象为 Heap File,并将其划分为多个 page,并且维护着一些信息,以此来跟踪读取或写入页面的数据。
Heap File 是存储 page 的无序集合,因此 DBMS 应该提供创建、获取、写入、删除、迭代 page 的接口,一次让上层服务能够有效地利用 page。为了有效地利用 page,有两种管理 page 的方式:链表法(Linked List)和页目录法(Page Directory)
链表法(Linked List)
在该方法中,page 以链表的形式被关联起来了。为了有效地管理这些 page,Heap File 开头维护了一个 header page,用来存储空闲链表(free page list)和数据链表(data page list)的引用。
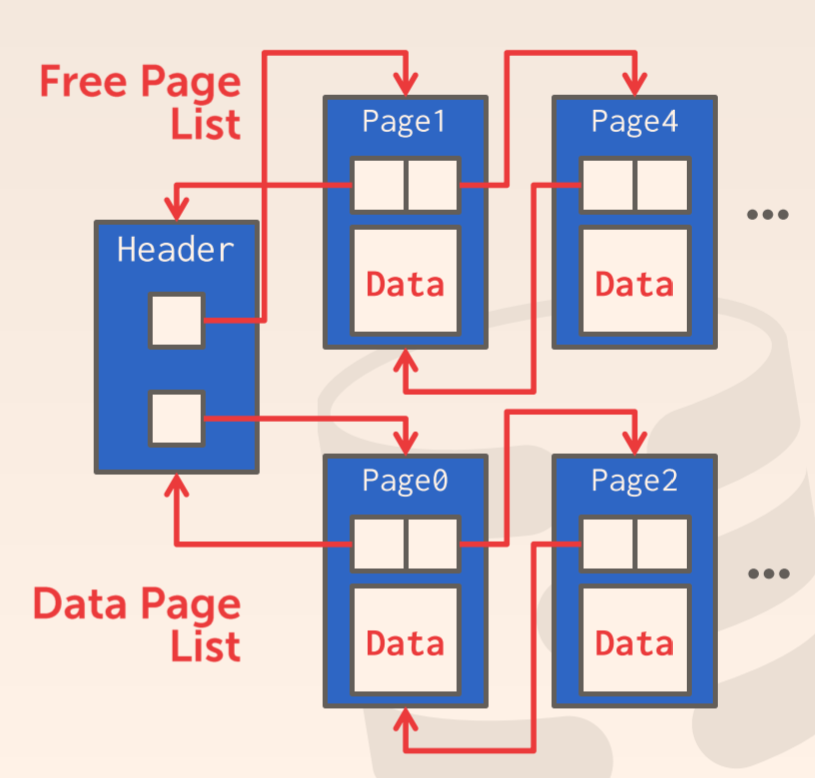
当我们需要访问页面时,只需要读取 header page,获取数据链表的引用,然后遍历链表便能够找到我们需要的数据。当需要分配一个新页面时,只需要从空闲链表中移除一个页面加入数据链表即可。
页目录(Page Directory)
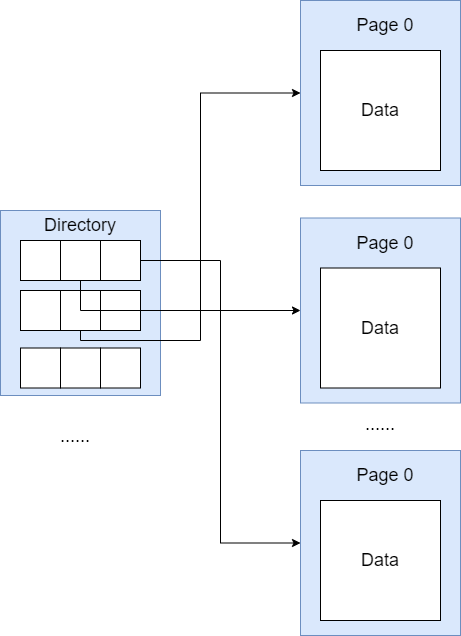
在 Page Directory 方法中,DBMS 维护了一个目录页,用来跟踪数据库文件中的 pages。在目录页中存储了一个 solt 数组,每个 solt 要么为空,要么存储着指向特定页面的引用。当需要创建页面时,只需选出一个空闲的 slot,将其指向新创建的页面即可。当需要访问页面时,只需要从已使用的 solt 中找到指定页面的引用
页面布局
知道 DBMS 是如何组织 pages 之后,我们接下来了解一下 DBMS 是如何组织数据的。
DBMS 组织数据的方式大致可以分为两种,一种是记录 tuple(Tuple-oriented),一种是记录日志(Log-Structured)。
Tuple-oriented
DBMS 将数据组织为 tuple,并将其存储在 page 中。
最简单的实现方式维护 tuples 的数量,然后将数据添加到 page 中。但是这种方法会带来很多问题,比如删除 tuples 时会形成碎片,因为 tuples 中可能由变长属性,所以访问 tuples 时只能遍历整个 page。
我们可以在 page 中维护一个 slots 数组,每个 slot 存储 tuple 在该 page 中的偏移量。为了方便对 page 进行操作,我们可以在 page 开头维护一个 header,记录 slots 的数量以及第一个未使用 slot 的偏移。当我们需要访问一个 page 时,我们可以通过 page_id,利用 Linked List 或者 Page Directory 找到相应的页面,然后通过 slot 中的偏移量,找到相应的 tuple。也就是说我们可以通过 page_id + offset/slot 的方式来定位一个 tuple。同理,当需要创建 tuple 时,我们只需要将 tuple 添加到 page 中,并将其偏移量记录在一个未使用的 slot 中。
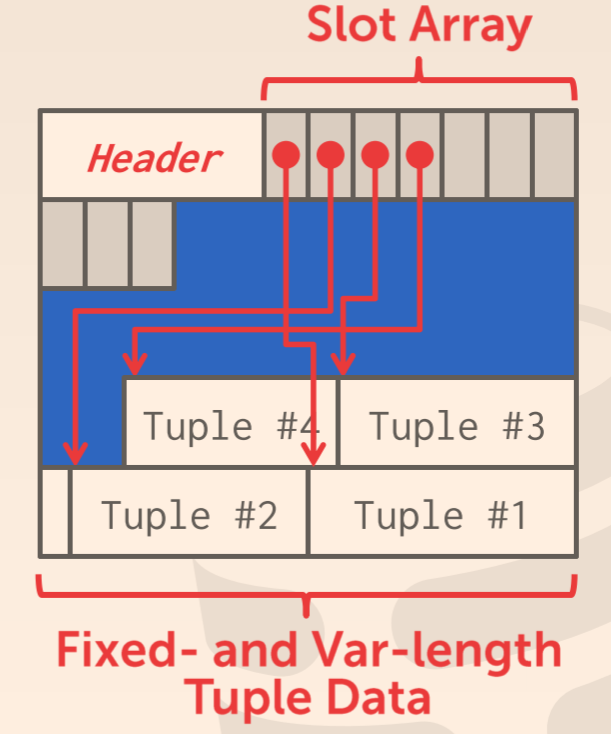
MySQL 的 Innodb 引擎的页面采用的就是这种方法。只不过 MySQL 将记录进行分组,每个 slot 指向一组 tuples 中的 key 最大的(即最后一个)tuple,并且 tuple 之间是以链表的形式连接的。
Log-Structured
在 Log-Structured 中,DBMS 不存储 tuple,而是存储日志。当数据库修改时,就向日志中添加一个日志记录;当读取数据时,向后扫描日志文件,回放记录。
Log-Structured 适合处理写操作,因为它将对数据随机写操作转换为了顺序写。但是面对读操作时,我们必须扫描日志,找到记录创建的位置,然后回放记录。
为了解决读取慢的问题,我们可以构建索引,用来跳转到日志中创建记录的位置,也可以定期压缩日志,减少读取的日志数量。
Tuple 布局
关系模型并没有强制要求将 tuple 的属性都存在一个 page 中,我们既可以将 tuple 的属性放在一起,以行的形式存放,亦可以将 tuple 的每个属性以列的形式存储。将 tuple 属性放在一起的方式称之为 N-Ary Storage Model(NSM,行存储),将 tuple 的每个属性单独成行,以列的形式存储的方式称之为 Decomposition Storage Model(DSM,列存储)。
行存储和列存储都有各自的优缺点。比如行存储方便 tuple 的写操作(如插入,更新,删除等),而且对于需要整个 tuple 的查询来说十分方便。但是如果只需要查询部分属性会占用更多的内存。而列存储正好相反,对于只需要部分属性的查询很方便,但是对于 tuple 的写操作很复杂(需要根据 id 找到其他属性更新)
为了描述一个 tuple,每个 tuple 都有一个 Header,包含 tuple 的 metadata(包括 Visibility info、Bit Map for NULL values)用来描述 tuple 的一些信息




