
cache 简要介绍
概述
随着存储技术的发展,CPU 和主存之间的速度差距已经非常大了。为了弥补 CPU 与主存之间的速度差异,通常会在 CPU 与主存之间添加若干个中间层,这种组织存储器系统的方法被称为存储器层次结构。
在存储器层次结构中,从高层往低层走,存储设备逐渐变慢,存储容量更大,价格更便宜,这一点与存储器制作的材料有关。一般最快的是 L0 缓存中的 CPU 寄存器,其次是基于 SRAM 的高速缓存存储器 L1、L2 等。再往下就是基于 DRAM 的主存存储器,然后是慢速的硬盘。为了使用最小的造价获取最大的收益,上层小而快的设备会作为下层大而慢的设备的缓存,如果所需数据在缓存中,就可以直接从缓存中获取数据。只有当缓存中不存在时,才会访问下层设备,并将数据存放到缓存中。
这样的存储结构之所以是有效的,得益于局部性原理。局部性包括时间局部性和空间局部性:
- 时间局部性:被引用过一次的内存位置很可能在不远的将来再次被引用
- 空间局部性:如果一个内存位置被引用了一次,那么程序很可能在不远的价格你来引用附近位置的内存
上层设备与下层设备之间的数据传送是以块(block)为单位的,也就是说如果想要访问地址 A 上的数据时,上层设备会拷贝 A 所属的整个块的数据。因为程序的执行具有空间局部性,所以将数据信息以块为单位缓存能够很好地较少访问下层设备的次数,从而减少访问的时间。
那么我们必须解决如下问题:
- 如何划分块
- 如何映射
- cache 满时怎么办
- 写数据时怎样保证 cache 和 MM 的一致性
- 如何根据主存地址访问到cache中的数据
通用的缓存存储器结构
我们知道,数据是存储在存储器中的,所以我们需要根据地址到存储器中取数据。因此我们可以将地址进行划分,让它具备相应的含义,以便我们更加有效的利用缓存。由于缓存是分块的,所以我们可以从地址中划分出 b 位用来表示块内偏移,这样当找到相应的块时,我们就可以通过块内偏移找到数据了。除去 b 位的块内偏移,剩下的我们可以用来表示块号,方便我们找到地址所属的块。
为了更好地管理块,我们可以将块进行分组,因此,我们可以从块号地址中划分出 s 位表示组索引,剩下的部分表示标记。
考虑这样一种情况,当缓存中的数据失效时(比如 Cache 被冲刷),这样我们根据地址到 Cache 中访问的数据根本就不是我们想要的数据。为了避免这种情况的发生,我们还需要一个有效位,用来标记缓存是否有有效。这个有效位可以在 Cache 中标记,并不需要从地址中单独划分出来一位。我们将 Cache 这样的一个块成为缓存行(cache line)
一个通用的缓存存储器的结构如下图所示。
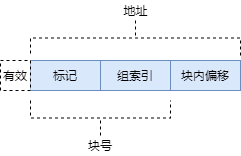
- 开机或复位时,所有行的有效位 V = 0
- 装入新块或某行被替换后 V = 1
- 冲刷 Cache 时 V = 0(如进程切换,DMA 传送)
cache 映射
我们知道,上层存储器相对于下层存储器来说容量更小,所以如何将上层缓存中的块映射到下层存储器中便成为了一个问题。下面我们将会介绍直接映射、组相联映射和全相联映射三种映射方式。
直接映射
直接映射是一种相当暴力的映射方法。既然缓存中的块比存储器中的块少,那么我就直接对块号取模操作,这样存储器中的一个块可以唯一地映射到缓存中的块中。比如 Cache 中有 16 个缓存行,而存储器中有 100 个块,那么第 23 号块将会被映射到 Cache 中的 (23 % 16) = 7 号块中。
这样的分法对应到 Cache 的通用结构中就是将将 Cache 中的 n 块分为 n 组,即每一组中只存放一个 Cache 行。
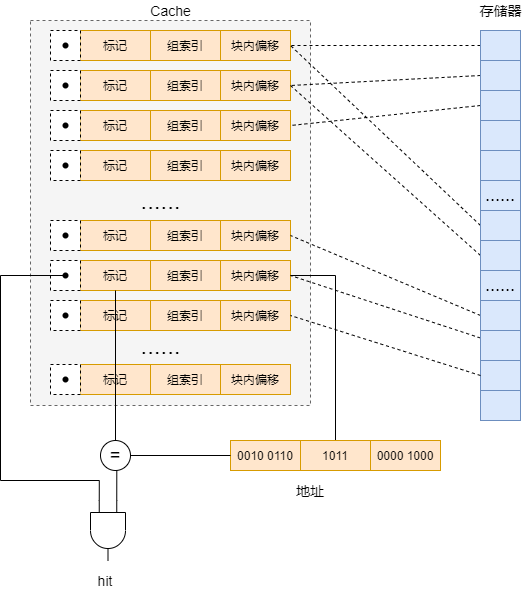
Cache 确定一个请求是否命中,然后抽取出被请求内容的过程分为三步:1) 组选择 2) 行匹配 3) 字抽取
- 组选择:根据地址中组索引部分找到 Cache 中相应组号的组。比如图中组索引部分为 1011那么可以找到 Cache 中的第 11 组
- 行匹配:由于直接映射只有一行,所以找到相应的组就行了。找到相应的行后,需要判断该行是否有效,如果无效则表示请求没有命中,否则再对比行中的标记是否与地址中的标记是否匹配。比如图中地址的标记为为 0010 0110,那么只有当匹配到的行的有效位有效,且标记位位 0010 0110 时才表示命中。
- 字抽取:根据地址中偏移部分的内容,找到块中相应的内容。比如图中地址块内偏移部分为 0000 1000,那么匹配行中的偏移量位 0000 1000 出的内容即为请求内容。
直接映射方式实现简单,而且不需要考虑缓存的替换问题。但是这种方法不够灵活,Cache 的存储空间不能得到充分利用。比如 Cache 有 8 行,而请求按照 0、8、16… 的顺序访问的话,在任意时刻,Cache 中只有第 0 块得到了利用,而且频繁换进换出根本无法利用到 Cache 的特点。
全相联映射
全相联映射将 Cache 只分为一组,也就是说存储器中的每一块都可以装入到 Cache 中的任意一行中。既然只有一组,那么我们也没有必要单独留出一位来表示组索引了,即块号的长度全部用来标记。
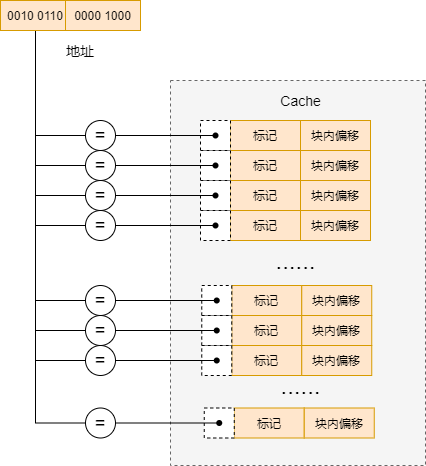
在全相联映射中确定一个请求是否命中的过程同样分为两步步:1) 行匹配 2) 字抽取
- 行匹配:抽取出地址中的标记部分,分别与每一个 Cache 行进行比较,如果有一行的有效位为有效,并且标记位匹配,则表示命中。
- 字抽取:根据地址中偏移部分的内容,找到块中相应的内容。
全相联映射方式没有冲突不命中,因为需要缓存的数据可以放在任意一个空 Cache 行中。但是在进行行匹配的时候的成本比较大。因为在全相联映射中,一个 Cache 行的标记位比较长,这就导致比较器需要比较的位数比较长,而且在进行行匹配时需要与所有的 Cache 行进行匹配。
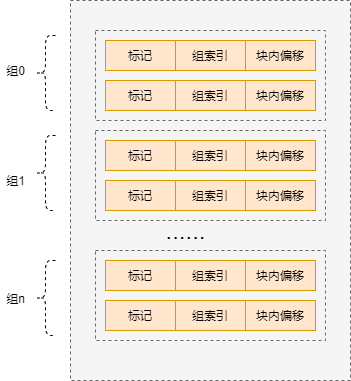
组相联映射
组相联映射将 Cache 分为若干组,每一组中有若干个 Cache 行。我们可以将组相联映射看成是直接映射和全相联映射的结合,先通过取模操作将块分组,一个块可以放在组内的任意一个位置。组相联映射的示意图如下图所示。
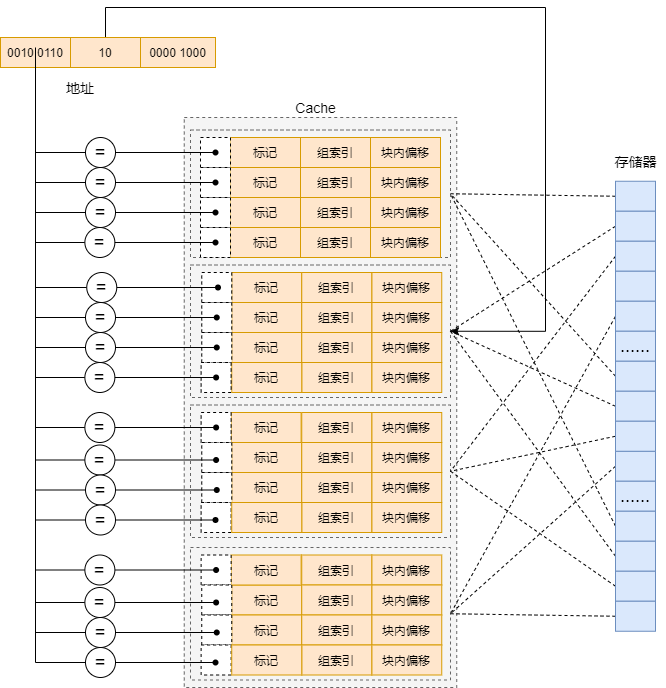
在全相联映射中确定一个请求是否命中的过程同样分为两步步:1) 组选择 2) 行匹配 3) 字抽取
- 组选择:根据地址中组索引部分找到 Cache 中相应组号的组。比如图中组索引部分为 10那么可以找到 Cache 中的第 2 组、
- 行匹配:抽取出地址中的标记部分,分别与每一个 Cache 行进行比较,如果有一行的有效位为有效,并且标记位匹配,则表示命中。
- 字抽取:根据地址中偏移部分的内容,找到块中相应的内容。
替换策略
由于 Cache 与存储器之间的容量存在很大的差距,所以 Cache 总会被填满,这时我们就必须要考虑替换策略来替换 Cache 中的内容了。对于直接映射,存储器中的一个块只能映射到 Cache 中指定的位置,所以直接替换就行了。但是对于全相联映射和组相联映射,存储器中的一个块可以映射到对应组中的任意一个 Cache 行,这是我们就必须采用适当的替换策略了。下面我们来介绍几种替换策略。
先进先出 FIFO
最容易想到的就是先进先出(FIFO)算法了。FIFO 算法借鉴了我们生活中排队的场景,选择最先进入 Cache 的行替换。这种方法十分简单,但是并不有效。当我们循环顺序访问数据时,有可能导致将要访问的数据刚好在上一次就被替换出去了,因此 FIFO 的命中率不会很高。
最近最少用 LRU
接下来,我们考虑将最近最少使用的行替换出去,这样就有了我们的最近最少使用(LRU)算法了。
在 LRU 算法中,我们给每一个 Cache 行设置一个计数器,用于记录每个 Cache 行已经多久没有被访问了。计数器的技术规则如下:
- 命中时,所命中的行计数器清零,比其低的计数器加 1,其余不变
- 未命中且还有空闲行时,新装入的行计数值置 0,其余非空闲行计数器值加 1
- 未命中且无空闲行时,计数值最大的行被淘汰,新装入行计数值置 0,其余全加 1
LRU 算法很好地利用了局部性原理,让最近访问次数多的块留在了缓存中,因此命中率很高。
最少使用 LFU
最少使用(LFU)算法就比较严格了,它将 Cache 中最少使用的行淘汰。同样,我们给 Cache 中的每一行设置一个计数器,当要替换时,将计数器最小的行替换。计数器的规则如下:
- 命中时,所名中行计数器加 1
- 未命中且还有空闲行时,新装入行计数器置 0
- 未命中且无空闲行时,选择计数器最小的一行替换,计数器值置 0
写策略
由于缓存与存储器之间存在容量差,那么就必然会发生替换。如果缓存中的数据副本被修改了,那么缓存中的数据与存储器中的数据便会不一致。下面我们来探讨一下写 Cache 的问题(下面的讨论不考虑并发的情况)。
当写命中时,我们可以两种策略:
- 直写(write through):写 Cache 的同时写存储器
- 回写(write back):只写 Cache,不写主存,替换时才将 Cache 写回主存
我们先来看一下回写策略,这种方法时只写缓存。这种方法充分利用了 Cache 快速的特性,但是会发生 Cache 与存储器中数据不一致的问题,所以我们需要在替换的时候将 Cache 中的数据写回到存储器中。
我们可以给 Cache 添加一个 dirty 位,用来标识 Cache 是否被修改过了。如果 dirty 位为 1,表示 Cache 已经被修改过了,替换时我们需要写回主存。如果 dirty 位为 0,表示 Cache 没有被修改过,这时可以不写回主存。
接下来我们看一些直写策略。这种方法在写 Cache 的同时写存储器,所以 Cache 和存储器中的数据一直都是相同的,没有一致性问题。但是这种操作很慢,所以我们必须想出一种方法来加快写操作。
我们可以添加一个写缓冲区(write buffer),写 Cache 时我们不写存储器,而是向 buffer 中写,buffer 由存控设备(Memory controller) 写回存储器。这种方法提高了写操作的速度,但是当 buffer 满时,所有的写操作只能阻塞,等待 buffer 写回存储器。对此,我们可以使用二级 Cache 来缓和这种情况。
接下来我们来看一下写不命中的情况。写不命中有两种策略:
- 写分配(write allocate):写不命中时,将块装入 Cache,一般与回写策略配合使用。
- 非写分配(not write allocate):直接写主存单元,一般与直写策略配合使用。
现代设备一般都会使用多级缓存,在缓存之间使用直写 + 非写分配的方法,在缓存与主存储器之间采用回写 + 写分配的方法。

参考资料

